
Notatki o testowaniu: WebDriver - łatwe i przyjemne testowanie aplikacji webowych
Każdy, kto ma choćby minimalne doświadczenie z testami doskonale zdaje sobie sprawę, że nawet najbardziej solidne testy jednostkowe nie dają stuprocentowej pewności poprawnego działania aplikacji. Często musimy spojrzeć na aplikację oczami końcowego użytkownika i zweryfikować, czy wszystkie zaimplementowane i przetestowane jednostkowo funkcjonalności są dla niego dostępne i działają tak jak sobie tego życzy.
W drugiej części serii Notatki o testowaniu chciałbym zaprezentować Wam narzędzie WebDriver, które pozwala tworzyć automatyczne testy funkcjonalne aplikacji internetowych. W połączeniu z poznanym już easyb sprawia, że pisanie testów to czysta przyjemność.
Co oferuje WebDriver?
WebDriver oferuje dwie kluczowe funkcjonalności, które czynią to narzędzie wartym uwagi. Z jednej strony to bardzo wygodne dla programisty API pozwalające na interakcję z przeglądarką, z drugiej zaś to koncepcja sterowników (ang. driver), które tę bezpośrednią komunikację umożliwiają. W tej sekcji przyjrzymy się obu tym aspektom. W drugiej części artykułu wykorzystamy przedstawioną tu wiedzę do stworzenia prostego scenariusza testowego.
WebDriver oferuje obsługę następujących przeglądarek:
- Internet Explorer,
- Firefox,
- Chrome.
W fazie eksperymentalnej dostępna jest także integracja z iPhone i z telefonami z systemem Android.
Dodatkowo otrzymujemy także HtmlUnitDriver, czyli implementację korzystającą z bezokienkowej przeglądarki napisanej w całości w Javie. Zyskujemy zatem przy jej pomocy możliwość uruchamiania testów na wielu platformach. To co odróżnia WebDrivera od innego znanego narzędzia jakim jest Selenium, to fakt, że ten pierwszy dostarcza natywnego dostępu do przeglądarki, drugi zaś opiera się o warstwę pośredniczącą jaką jest JavaScript. W przypadku WebDrivera oznacza to wykorzystanie technologii, które dają największe możliwości interakcji z przeglądarka. Jest to oczywiście dodatkowy wysiłek dla programistów tej biblioteki, ponieważ muszą rozwijać i utrzymywać tyle różnych implementacji ile wspieranych przeglądarek. Na przykład dla przeglądarki Internet Explorer natywny dostęp oznacza wykorzystanie C++, komponentów COM i gimnastyki z API stworzonym przez programistów z Redmond. Dla Firefox napisana została specjalna wtyczka.
Interfejs programistyczny oferowany przez WebDrivera jest minimalistyczny i intuicyjny zarazem. Dostarcza podstawowych operacji, które wykonuje na co dzień użytkownik przeglądarki. Zanim jednak przejdziemy do ich omówienia warto wspomnieć w jaki sposób możemy wyszukiwać elementy dostępne na stronie. WebDriver oferuje nam następujące metody:
- na podstawie unikalnego identyfikatora (id),
- określonej klasy CSS,
- nazwie elementu HTML (tagu),
- nazwie (atrybutu name),
- selektorów CSS3,
- tekstu bądź jego fragmentu znajdującego się w elemencie.
Dwa główne interfejsy, z których korzystać będziemy najczęściej podczas tworzenia testów korzystających z WebDrivera, to WebElement oraz WebDriver. Pierwszy z nich umożliwia interakcję z elementami dostępnymi na stronie. Tak więc możemy na przykład:
- kliknąć w wybrany element (o ile to ma sens),
- dowiedzieć się z jakim elementem HTML mamy do czynienia, jakie posiada atrybuty itd.,
- jeśli jest polem tekstowym możemy w nim coś napisać bądź wyczyścić jego zawartość,
- wyszukać elementy znajdujące się w poddrzewie DOM, dla którego korzeniem jest dany element,
- wysłać zawartość formularza.
Warto podkreślić tutaj, że API to ma charakter blokujący. Oznacza to, że każda operacja skutkująca przeładowaniem strony spowoduje zatrzymanie wykonywania testu i oczekiwanie na zakończenie tej operacji w przeglądarce. Oczywiście dostępny jest także deklaratywny mechanizm oczekiwania na jakieś zdarzenie, który może być szczególnie pomocny przy testowaniu silnie AJAXowych aplikacji.
WebDriver, czyli drugi kluczowy interfejs narzędzia o tej samej nazwie, oferuje nam z kolei operacje typowe dla przeglądarki jako programu. Możemy zatem załadować wybraną stronę wpisując jej URL w pasek adresowy, przełączać się pomiędzy oknami, używać funkcji Wstecz i Dalej, odświeżać stronę a nawet manipulować ciasteczkami.
Bardzo ciekawym pomysłem promowanym przez twórców tego narzędzia jest wzorzec Page Object. Najprościej rzecz ujmując jest to klasa enkapsulująca fragment (kontrolkę) strony i dająca możliwość interakcji z nią poprzez przejrzysty zestaw metod. Jest to nie tylko zaleta w postaci czytelnego kodu, ale także możliwość wykorzystywania tak przygotowanych fragmentów w wielu scenariuszach testowych. Przykładowy scenariusz stworzony na potrzeby tego artykułu nie tylko bazuje na tej koncepcji, ale również ilustruje w jaki sposób API WebDrivera ją wspiera.
Funkcjonalność, której brakować może wielu programistom, a w szczególności testerom, jest brak odpowiednika SeleniumIDE – narzędzia do nagrywania interakcji użytkownika z przeglądarką, które może ułatwić tworzenie testów i zwiększyć produktywność. Z drugiej strony programista wyposażony w takie dodatki Firefox jak Firebug i XPather (lub XPath Checker) nie powinien mieć wielkich trudności w implementowaniu nawet najbardziej wymyślnych scenariuszy testowych. Twórcy WebDriver wyszli jednak naprzeciw temu ograniczeniu dostarczając adapter API Selenium. Dzięki temu wciąż możemy używać stworzone wcześniej za pomocą SeleniumIDE testy, ciesząc się przy tym z możliwości jakie oferuje nam WebDriver.
Scenariusz testowy
Posiadamy już podstawową wiedzę na temat możliwości jakie daje nam WebDriver, możemy zatem bez obaw przejść do praktycznego jej zastosowania. W tym celu stworzymy prosty scenariusz testowy:
- Użytkownik wchodzi na stronę http://dzone.com,
- wyszukuje skatalogowane strony zawierające frazę "java express",
- oczukuje, że na liście rezultatów dostępny jest link do strony magazynu Java exPress.
Korzystając z poznanego już easyb stwórzmy zatem wstępną formę scenariusza:
scenario "Searching for Java exPress magazine link on dzone.com", {
given "user is on dzone.com main page"
when "he searches for ‘java express’"
then "link to the javaexpress.pl website should be present in the results list"
}
Dla uproszczenia zweryfikujemy, że wśród wyświetlonych rezultatów znajduje się taki, którego tytuł to "Free Java exPress newsletter available".

Rys 1. Strona główna dzone.com. W prawym górnym rogu zaznaczona została wyszukiwarka, którą użyjemy w naszym teście.
Patrząc z perspektywy użytkownika musimy wykonać dwie czynności:
- Wpisać w polu tekstowym frazę "java express".
- Nacisnąć przycisk z lupą (bądź klawisz enter) w celu uruchomienia wyszukiwarki.
Mając dostęp do tych dwóch elementów strony z poziomu API WebDriver powyższe czynności możemy zaimplementować w dwóch linijkach kodu:
searchBox.sendKeys("\"java express\"");
searchButton.click();
Oba te elementy dostępne są dzięki odpowiednim atrybutom id, co potwierdza poniższy listing:
<div id="mh_search">
<form method="get" action="/links/search.html" id="headerSearch">
<input type="text" size="20" name="query” id="mh_searchQuery" />
<input type="image" id="mh_searchSubmit" alt="Submit"/>
</form>
</div>
Klasa realizująca wzorzec Page Object, która umożliwiałaby użycie wyszukiwarki dostępnej na stronie dzone.com mogłaby mieć następującą postać:
public class DzoneMainPage {
private static final String DZONE_PAGE = "http://dzone.com";
// Pole typu WebDriver umożliwia interakcję z wyświetlanymi przez
// przeglądarkę stronami.
private final WebDriver driver;
// Element odpowiadający polu tekstowemu zlokalizowany będzie po ID
@FindBy(how = How.ID, using = "mh_searchQuery")
private WebElement searchBox;
// Element odpowiadający przyciskowi uruchamiającemu wyszukiwanie zlokalizowany
// będzie po ID
@FindBy(how = How.ID, using = "mh_searchSubmit")
private WebElement searchButton;
public DzoneMainPage(WebDriver driver) {
this.driver = driver;
// Strona http://dzone.com zostanie załadowana przez przeglądarkę
driver.get(DZONE_PAGE);
}
public DzoneSearchResultPage searchFor(String query) {
searchBox.sendKeys(query);
searchButton.click();
// Wyszukiwarka przenosi nas na stronę z rezultatami. Dzięki
// PageFactory mamy dostęp do instancji klasy DzoneSearchResultPage,
// której pola WebElement zostały właściwie zainicjalizowane.
return PageFactory.initElements(driver, DzoneSearchResultPage.class);
}
}
Wynik działania wyszukiwarki to strona z listą artykułów pasujących do podanej frazy (rysunek 2).
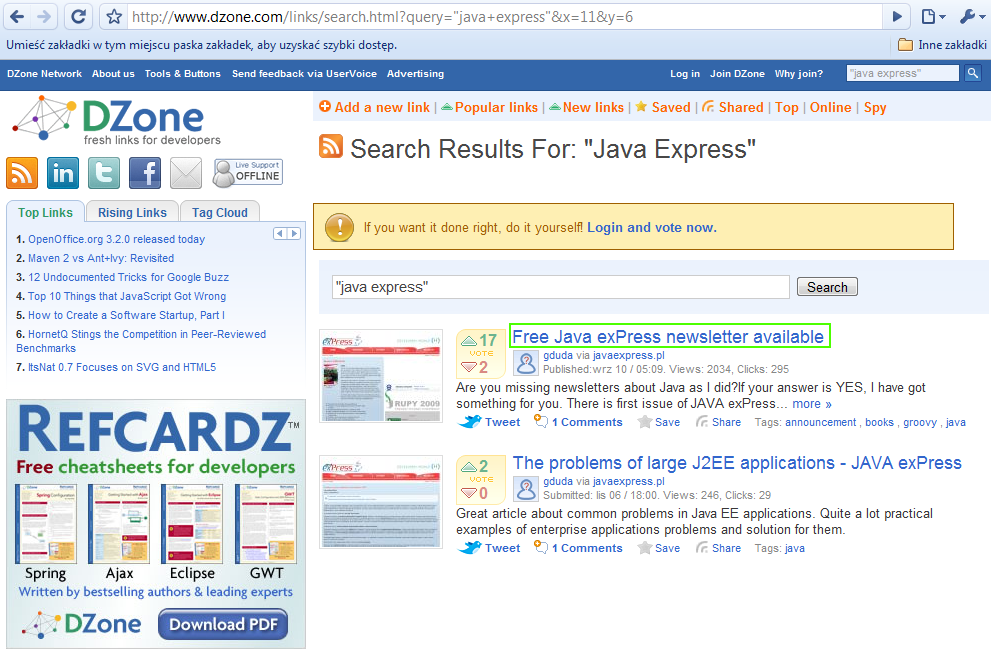
Rys 2. Strona z rezultatami wyszukiwania „java express”. W zielonej ramce wyróżniony został tytuł, którego obecność weryfikujemy w scenariuszu testowym.
<div class="details">
...
<h3><a href="..." rel="bookmark">Free Java exPress newsletter available</a></h3>
...
</div>
Kod przedstawiony na powyższym listingu podpowiada nam w jaki sposób możemy zlokalizować na stronie wynikowej wszystkie tytuły artykułów. Wykorzystując XPath możemy zapisać to w następujący sposób:
//div[@class='details']/h3/a
Powyższe wyrażenie mówi mniej więcej tyle – znajdź wszystkie elementy <a>, których rodzicem jest <h3>, którego z kolei rodzicem jest <div> posiadający klasę details. To wystarczy, aby stworzyć klasę DzoneSearchResultPage, którą wykorzystamy w testach.
public class DzoneSearchResultPage {
// Wyrażenie XPath pozwalające na zlokalizowanie wszystkich
// tytułów na stronie rezultatów.
private static final String SEARCH_RESULT_TITLES_XPATH =
"//div[@class='details']/h3/a";
private final WebDriver driver;
public DzoneSearchResultPage(WebDriver driver) {
super();
this.driver = driver;
}
public List<String> getSearchResultTitles() {
// Elementy pobierać można również korzystając bezpośrednio z drivera
List<WebElement> elements =
driver.findElements(By.xpath(SEARCH_RESULT_TITLES_XPATH));
// Wygodny sposób transformacji kolekcji obiektów z jednego typu
// na drugi, dostępny w bibliotece Google Collections.
List<String> results = Lists.transform(elements, new ExtractText());
return results;
}
/**
* Klasa wykorzystana do transformacji obiektów klasy WebElement
* na String.
*/
private final class ExtractText implements Function<WebElement, String> {
@Override
public String apply(WebElement from) {
return from.getText();
}
}
}
Stworzyliśmy kompletny mechanizm emulujący interakcję użytkownika ze stroną dzone.com, możemy zatem uzupełnić nasz scenariusz easyb:
before "Start WebDriver", {
// Przed wykonaniem scenariuszy uruchamiamy przeglądarkę.
// W tym przypadku będzie to Mozilla Firefox.
driver = new FirefoxDriver()
}
scenario "Searching for Java exPress magazine link on dzone.com", {
given "user is on dzone.com main page", {
mainPage = PageFactory.initElements(driver, DzoneMainPage.class)
}
when "he searches for ‘java express’", {
searchResultPage = mainPage.searchFor("\"java express\"")
}
then "link to the javaexpress.pl site should be present in the results list", {
titles = searchResultPage.getSearchResultTitles()
titles.shouldHave "Free Java exPress newsletter available"
}
}
after "Close WebDriver", {
// Po wykonaniu wszystkich scenariuszy zamykamy przeglądarkę.
driver.close()
}
Teraz wystarczy już tylko uruchomić scenariusz z poziomu Anta, Mavena bądź pluginu dla środowiska Eclipse czy IntelliJ IDEA. WebDriver zajmie się za nas całą resztą.
Podsumowanie
Artykuł ten prezentuje jedynie namiastkę możliwości WebDrivera. Biblioteka ta oferuje znacznie więcej – jak chociażby wsparcie dla AJAX oraz innych języków (Python i Ruby), separację pomiędzy przeglądarką a systemem, na którym uruchamiane są testy (moduł RemoteWebDriver), robienie zrzutów ekranu czy wsparcie dla mechanizmu drag&drop. Warto tutaj wspomnieć, że WebDriver stosowany był do testów aplikacji Google Wave, a programiści tego projektu aktywnie uczestniczyli w jego rozwoju.
Oczywiście, jak każde dzieło ludzkie, WebDriver też nie jest pozbawiony wad. Przede wszystkim największym wyzwaniem jest zapewnienie działania sterowników przeglądarek w jak największej liczbie systemów operacyjnych. Problemy z ewaluacją wyrażeń XPath oraz szybkością działania testów, które z nich korzystają to kolejna zmora, szczególnie jeśli wymogiem stawianym naszej aplikacji jest wsparcie starszych wersji Internet Explorera. Mądrym podejściem wydaje się zatem wykorzystywanie tej techniki tylko w skrajnych przypadkach. Z własnego doświadczenia wiem także, że testowanie w przeglądarce z niebieskim E w logotypie nie zawsze gwarantuje nam powtarzalność testów. Strona często ładuje się zbyt długo, na przykład z bliżej niewyjaśnionych przyczyn oczekując w nieskończoność na obrazek, który tak naprawdę jest już widoczny. Powoduje to wyjątki WebDrivera i dominację czerwonego koloru w raportach z testów. Nie jest to jednak najprawdopodobniej ułomność omówionego w tym artykule narzędzia, a raczej problemy samej przeglądarki bądź konfiguracji systemu.
Na koniec pozostaje mi tylko wytłumaczenie, dlaczego w tym artykule brakuje dokładnego porównania WebDrivera z chyba najbardziej znanym narzędziem do automatycznych testów funkcjonalnych aplikacji webowych, czyli Selenium. Powód jest niezwykle prosty – twórcy obu projektów postanowili połączyć siły i począwszy od drugiej wersji Selenium, WebDriver staje się jego integralną częścią. Oba narzędzia już wprowadziły wiele innowacji, aż strach pomyśleć co będzie owocem prac tego tandemu :)
Źródła
- http://webdriver.googlecode.com/ - strona projektu WebDriver.
- http://code.google.com/p/google-collections/ - strona projektu Google Collections
- http://www.youtube.com/watch?v=tGu1ud7hk5I – prezentacja z Google Test Automation Conference.
- http://code.google.com/p/bmajsak-javaexpress/ - projekt stworzony na potrzeby tego artykułu


Nobody has commented it yet.