
J2ME: Serializacja obiektów, cz. I
Wstęp
"Pickling is the process of creating a serialized representation of objects."
Antonio J Sierra,
"Recursive and non-recursive method to serialize object at J2ME"
Mechanizm serializacji (Java™Object Serialization Specification, [1]) pozwala na przechowywanie stanów obiektów pomiędzy kolejnymi wywołaniami programu, a także na przesyłanie obiektów przez sieć. Kluczem do zapisywania i odczytywania obiektów jest taka reprezentacja ich stanu, aby możliwa była późniejsza rekonstrukcja. Działa to nawet w sieci, co oznacza, że mechanizm serializacji automatycznie kompensuje różnice między systemami operacyjnymi. Serializacja obiektów umożliwia zaimplementowanie "lekkiej trwałości" (lightweight persistence, "Thinking in Java" ch.12). Serializacja została dodana do języka, aby umożliwić zdalne wywoływanie metod (RMI) oraz jest mechanizmem niezbędnym w przypadku komponentów JavaBeans. Stan serializowanego obiektu reprezentowany jest najczęściej w postaci strumienia bajtów. Klasa obiektu, który ma być przechowywany/przesyłany, musi być serializowalna, tzn. musi implementować interfejs java.io.Serializable, jest to interfejs znacznikowy (marker interface, [2]), tzn. nie posiada żadnych metod, tylko informuje wirtualną maszynę Java'y, JVM, że obiekt może zostać zapisany. Ważną cechą serializacji jest zapis całej "sieci obiektów", z którą połączony jest pojedynczy obiekt. Dostajemy graf serializowanych obiektów. Procesem serializacji można sterować implementując interfejs java.io.Externalizable, który de facto i tak rozszerza java.io.Serializable. Do dyspozycji mamy dwie metody, które wywoływane są automatycznie podczas serializacji/deserializacji:
public void readExternal (java.io.ObjectInput in)
throws IOException, ClassNotFoundException;
public void writeExternal(java.io.ObjectOutput out)
throws IOException;
Interfejs ten jest wtedy użyteczy, gdy chcemy mieć pełną kontrolę nad serializacją i deserializacją tworzonych obiektów.
Sun documentation:
"...Externalizable interface are implemented by a class to give the class complete control over the format and contents of the stream for an object and its supertypes..."
Jeżeli nie podoba się komuś perspektywa implementowania interfejsu java.io.Externalizable to zawsze można pozostać przy java.io.Serializable, "dodając" metody:
private void writeObject(java.io.ObjectOutputStream out)
throws IOException;
private void readObject (java.io.ObjectInputStream in)
throws IOException, ClassNotFoundException;
...i tym samym jesteśmy w stanie przejąć kontrolę nad zapisywaniem i odczytywaniem stanu obiektu. W tym wypadku obiekt implementujący interfejs Serializable "pytany" jest, przy zastosowaniu mechanizmu refleksji, czy implementuje własną metodę writeObject(). Do zapisu stanu obiektu możemy użyć metod defaultWriteObject() lub writeFields(). Analogiczna rzecz dzieje się w przypadku readObject().
J2ME, czyli Java 2 Platform, Micro Edition, jest edycją Java'y przeznaczoną na pisanie aplikacji pod urządzenia o ograniczonych zasobach oraz małym budżetem pamięciowym (np. telefony komórkowe, PDA). Ze względu na ograniczenia techniczne takich urządzeń, czyli wolniejsze procesory i mniejsza pamięć, Java ME posiada własny, okrojony w stosunku do JSE, zestaw klas. Specyfikacja J2ME powstała w odpowiedzi na zapotrzebowanie ze strony urządzeń elektronicznych z tzw. "oprogramowaniem wbudowanym". Wiele pakietów z J2SE nie trafiło do J2ME a te, które zostały tu przeniesione ze standardowego zestawu pakietów, zostały mocno "okrojone". Architektura J2ME składa się z konfiguracji, profili oraz pakietów opcjonalnych. Na konfigurację składa się wirtualna maszyna Javy (KVM [3] – Kilobyte Virtual Machine, CVM [4], Monty VM [5], IBM's J9 VM [6], BlackBerry Motions's VM [7]) oraz podstawowy zestaw klas (tzw. klasy core'owe). Każdy producent urządzeń mobilnych implementuje swoją własną maszynę wirtualną. Jej budowa jest zależna od platformy systemowej urządzenia. Klasy core'owe zapewniają podstawową funkcjonalność urządzeniom o podobnych charakterystykach, czyli dostępna pamięć, moc obliczeniowa, rodzaj wyświetlacza, sposób wprowadzania danych czy też możliwość dostępu do sieci. Aktualnie istnieją dwie konfiguracje J2ME:
CLDC (Connected Limited Device Configuration)
CDC (Connected Device Configuration)
Konfiguracja urządzenia musi zostać powiązana z profilem. Najczęściej spotykane połączenie to CLDC 1.1 + MIDP 2.0 (Mobile Information Device Profile JSR 118). Na uwagę na pewno zasługuje NTT DoCoMo Java, zaimplementowana np. w telefonie Sony Ericsson k550i. Telefon ten korzysta z konfiguracji CLDC 1.1 oraz DoJa 2.5 API [8] DoJa jest to alternatywą dla profilu MIDP, oferuje między innymi interfejs do obsługi kamery, wysyłania/odbierania SMS'ów czy też API do obsługi grafiki 2D/3D (Mascot Capsule Micro3D). Na bazie wybranej konfiguracji i profilu tworzone są aplikacje zwane MIDletami, wśród których wyróżnić możemy gry lub inne aplikacje wykorzystywane w biznesie. Instalacja aplikacji na urządzeniu mobilnym sprowadza się do skopiowania pliku JAR (Java Archive) i JAD (Java Application Descriptor) przy pomocy kabla, IRDy, Bluetooth lub technologi GPRS na dane urządzenie. Nasze możliwości co do "pisania" programów niewątpliwe rosną wraz z użyciem pakietów opcjonalnych. Pakiety te rozszerzają platformę J2ME o dodatkowe funkcjonalności (API), z których programiści w ramach danego urządzenia mogą korzystać. Należy mieć na uwadze iż nie wszystkie pakiety są standardowo dostępne na każdym telefonie. Sony Ericsson k550i nie obsługuje np. Location-API oraz SIP-API. Ogólnie pakiety opcjonalne pozwalają np. na dostęp do baz danych (JSR 169), multimediów (JSR 135), protokołu bluetooth (JSR 82), web serwisów (JSR 172) czy nawet grafiki 3D (JSR 184).
Przedstawienie problemu
Niestety mechanizm serializacji obiektów nie działa w przypadku J2ME, żadna z konfiguracji CLDC 1.0 (JSR 30) oraz CLDC 1.1 (JSR 139) nie obsługuje mechanizmu zapisu stany obiektów czy też refleksji.
Sun documentation:
"Consequently, a JVM supporting CLDC does not support … object serialization..."
Próba kompilacji np. klasy MyObject implementującej java.io.Serializable/Externalizable lub dodanie do classpath artefaktu zawierającego tę klasę w fazie preweryfikacji (badanie klas, które mają zostać wczytane przez maszynę wirtualną zgodną z CLDC, np. KVM) kodu skutkuje wyrzuceniem następującego błędu:
Error preverifying class com.sonic.test.MyObject
java/lang/NoClassDefFoundError: java/io/Serializable
Problem ten można rozwiązać implementując własny mechanizm serializacji. Przykłady właśnie takich podejść można znaleźć na stronach [9] i [10]. Mając na uwadze to, iż nie możemy skorzystać z java.io.Serializable/Externalizable możemy stworzyć własny interfejs albo poszukać gotowych rozwiązań. Ja wybrałem interfejs udostępniany wraz z framework'iem J2ME Polish [11] o nazwie de.enough.polish.io.Externalizable. Po ściągnięciu można go znaleźć w artefakcie 'enough-j2mepolish-client.jar', który znajduje się w katalogu: ${polish.home}/lib/.
Interfejs ten udostępnia dwie metody:
public void write(final java.io.DataOutputStream dos)
throws java.io.IOException
public void read(final java.io.DataInputStream dis)
throws java.io.IOException
Obiekty DataOutputStream/DataInputStream będą reprezentować strumień danych, do którego będziemy pisać i czytać. Strumień jest pojęciem abstrakcyjnym. Oznacza tor komunikacyjny pomiędzy dowolnym źródłem danych, a ich miejscem przeznaczenia. Strumienie danych umożliwiają posługiwanie się różnymi typami danych. Filtrują połączone z nimi strumienie bajtów, pozwalając na zapis i odczyt prostych typów danych.
Sun documentation:
"...A data input stream lets an application read primitive Java data types from an underlying input stream in a machine-independent way..."
W ramach tych klas posługiwać będziemy się takimi metodami jak:
Pisanie do strumienia:
void writeX(x var);
gdzie X – nazwa typu danych. Na przykład:
void writeDouble(double var);
Czytanie ze strumienia:
x readX();
gdzie X – nazwa typu danych. Na przykład:
double readDouble();
Aby nasz system był uniwersalny będziemy musieli zatroszczyć się o przypadki, gdy w grę wejdą obiekty (np. kolekcje). Używając tych interfejsów, nie mamy metod typu readObject()/writeObject(). Na szczęście z pomocą przychodzi nam biblioteka SerME [12], która udostępnia prosty mechanizm serializacji i perzystencji danych do bazy (RMS, javax.miroedition.io.file) lub też narzędzie z tego samego framework'a o (J2ME Polish) nazwie: de.enough.polish.io.Serializer.
Użycie tego ostatniego sprowadza się do wywołania dwóch statycznych metod:
Serializer.serialize(MyObject, dos);
MyObject myObject = (MyObject) Serializer.deserialize(dis);
W tym momencie łatwo wyobrazić sobie naszą przykładową klasę MyObject zawierająca dwa prywatne pola 'name', 'myObject2' oraz metody get/set. Pole 'name' jest typu String, więc nie będzie problemu z serializacją. W przypadku pola 'myObject2', jeżeli tylko klasa MyObject2 implementuje interfejs:
de.enough.polish.io.Externalizable,
to wystarczy, że użyjemy klasy Serializer.
Listę typów danych obsługiwanych przez Serializer można zobaczyć pod adresem:
http://www.j2mepolish.org/cms/leftsection/documentation/programming/serialization.html.
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
public class MyObject implements de.enough.polish.io.Externalizable {
private String name = "";
// Klasa imlementująca de.enough.polish.io.Externalizable
private MyObject2 myObject2 = null;
public MyObject() { }
public MyObject(String name, MyObject2 myObject2) {
super();
this.name = name;
this.myObject2 = myObject2;
}
public void read(DataInputStream dis) throws IOException {
this.name = dis.readUTF();
this.myObject2 = (MyObject2)de.enough.polish.io.Serializer.deserialize(dis);
}
public void write(DataOutputStream dos) throws IOException {
dos.writeUTF(this.name);
de.enough.polish.io.Serializer.serialize(this.myObject2, dos);
}
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public MyObject2 getMyObject2() { return myObject2; }
public void setMyObject2(MyObject2 myObject2) { this.myObject2 = myObject2; }
}
W tym przypadku sprawa była bardzo prosta, mieliśmy tylko dwa pola, więc proces tworzenia implementacji do metod read()/write() był szybki i trywialny. Co w przypadku, gdybyśmy mieli 100 takich klas, a każda np. po 20 pól różnego typu? Pisanie kodu zajęłoby dużo czasu, łatwo o pomyłki i późniejsze błędy typu java.lang.ClassCastException występujące już w trakcie działania programu. Musielibyśmy też za każdym razem pamiętać o kolejności zapisywania i odczytywania danych w metodach read() i write(). Jeżeli w metodzie read(), z powyższego listingu, zamienimy kolejność odczytywania danych ze strumienia, to dostaniemy błąd:
java.io.EOFException
at java.io.DataInputStream.readFully(DataInputStream.java:178)
at java.io.DataInputStream.readUTF(DataInputStream.java:565)
at java.io.DataInputStream.readUTF(DataInputStream.java:522)
at MyObject.read(MyObject.java:23)
at MySerializationTest.main(MySerializationTest.java:37)
Chcielibyśmy stworzyć taki system, który sam tworzyłby cały kod, czyli pewnego rodzaju automat do generowania źródeł klas, który dosłownie "pisałby", to czego nam po prostu się nie chce. Ciała metod implementowane byłyby na podstawie pól klas i ich typów. Cały proces tworzenia odpalany byłby np. za pomocą Maven'a lub ANT'a. Aby było ciekawiej (trudniej), nasz system będzie musiał spełniać pewne założenia projektowe:
1. Elastyczność systemu ma być zapewniona poprzez integrację z zewnętrznymi interfejsami w postaci plików Schema. Integracja ta ma sprowadzać się stworzenia modelu danych (zmodyfikowanych klas POJO [zawierających gotowe implementacje metod read()/write()]) na podstawie plików *.xsd.
2. Generacja kodu wynikowego ma być w pełni zautomatyzowana, użytkownik systemu powinien jedynie zadbać o dostarczenie odpowiednich plików Schema.
3. Kod wynikowy klas musi się dać skompilować i uruchomić w środowisku J2ME.
4. Z uwagi na tak restrykcyjne środowisko, kod wynikowy powinien mieć jak najmniejszy rozmiar.
Próba rozwiązania
Co chcemy zrobić?
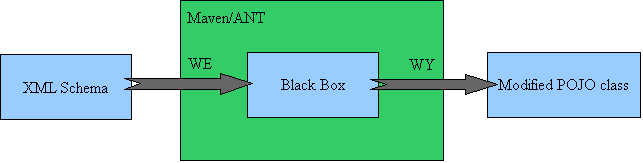
Rys. 1
Jest masa narzędzi/framework'ów w sieci, które potrafią stworzyć nam model danych, a co za tym idzie gotowy kod klasy, na podstawie plików Schema (XML, vocabulary grammar check). Wygenerowany kod najczęściej przyjmuje formę klasy JavaBean [13], czyli musi posiadać bezargumentowy konstruktor o dostępie publicznym, pola klasy (widoczność: private) dostępne są poprzez publiczne metody (accessor/mutator methods), klasa musi być serializowalna.
Do najbardziej popularnych framewok'ów można by zaliczyć JAXB [14], Apache XMLBeans [15], Castor Project [16] czy też (na razie w fazie eksperymentalnej) ASF [17] (Adaptive Serializer framework, SOA-J [18] – polecam) oraz mniej znane takie jak: Enhydra Zeus [19], Arborealis, from Beautiful Code BV [20], JBind [21], Quick [22].
W naszym projekcie użyjemy jednej z bibliotek Castora w wersji 1.2 (czyli nasz Black Box z rysunku nr 1). Biblioteka odpowiedzialna będzie za generowanie kodu źródłowego naszych klas. Klasy tworzone będą na podstawie plików Schema (W3C XML Schema 1.0 Second Edition, Recommendation), a biblioteka/tool, który się tym zajmie to Castor XML Code Generator.
Castor jest na tyle elastyczny, że pozwala programiście wpłynąć na proces generacji kodu. Proces ten może być kontrolowany poprzez zewnętrzne pliki (np. binding.xml). Plik ten definiuje relację (mapping) pomiędzy Java a XML i jest używany, jeżeli domyślne powiązanie nie spełni w jakiś sposób naszych oczekiwań. Co to oznacza? Domyślny mechanizm nie radzi sobie w przypadku gdy XML Schema dopuszcza takie same nazwy dla tagu <element> i <complexType>. Generator kodu wyprodukuje wtedy dwie klasy z taką samą nazwą (Fully Qualified Class Name), jednak później to ta ostatnia nadpisze tą pierwszą. Innym przykładem zastosowania jest zmiana domyślnego powiązania pomiędzy typami danych lub próba wprowadzenia ich własnych reguł walidacyjnych i co za tym idzie chęć poinformowania o tym generator kodu (SourceGenerator). Według mnie zastosowanie adnotacji (JAXB) w naszym przypadku nie jest zbyt dobrym rozwiązaniem. Za każdym razem, gdy będziemy chcieli zmienić mapping, trzeba będzie zmienić kod źródłowy, przekompilować klasy, a potem zrobić deploy na serwer, jest to dość czasochłonne. Innym minusem jest fakt, że niektórych typów mappingów po prostu nie da się zrobić stosując same adnotacje (np. multivariate type mappings). W tym wypadku najlepiej radzi sobie ASF, gdzie każdy mapping danego typu może posiadać wiele strategii jego użycia. Odpowiednia strategia (<startegy> element) wybierana jest w zależności od kontekstu, czyli nasze narzędzie samo dostosowuje się do naszych potrzeb. Mając też na uwadze SoC ( Separation of Concerns, SOA – Using Java Web Services, Mark D. Hansen, chapter 11.3) dobrym nawykiem w trakcie projektowania systemu powinna być separacja warstwy mappingu (mapping layer) od implementacji ( implementation layer). Właśnie ta separacja wpływa na to, iż w trakcie działania naszej aplikacji mapping może ulec zmianie, mało tego, mamy też możliwość obsługi wielu mappingów (w JAXB każda klasa ma tylko jeden "zestaw" adnotacji).
Mapping można przedstawić jako parę <J, X>, gdzie J jest to dowolny element Javy, a X dowolny komponent schemy.
Przykład:
foo:AddressType i foo.Address
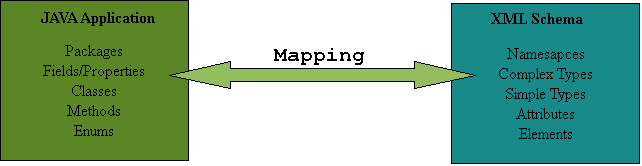
Rys. 2
Mapping jest przeprowadzany przez serializer, który zamienia poszczególne instancje klas Javy na instancje XML, które z kolei odpowiadają odpowiednim plikom schema (Java → XML). Funkcja odwrotna wykonywana jest przez deserializer (XML → Java). Mapping jest relacją, ale niekoniecznie funkcją, innymi słowy jedna i ta sama klasa Javy może zostać zmapowana do dwóch różnych plików schema. Mapping zachodzi w przypadku gdy mamy do czynienia zarówno z istniejąca już klasą Java oraz istniejącym plikiem Schema (rys. 2).
Z książki: "SOA Using Java Web Services", Mark D. Hansen, chapter 5.1:
"...type mapping you work with are between existing Java and existing XML schema definitions. At runtime, you will not be working with any machine-generated artifacts."
Mapping może być uważany jako swoistego rodzaju most między światem Javy a światem XML'a. Można by pokusić się o stwierdzenie:
"...an XML document is an instance of an XML Schema and an Object is an instance of a Class...".
Przy pomocy drugiej biblioteki Castor'a o nazwie Castor XML Data Binding odbywa się marshaling/unmarshaling. Co to jest Marshal?
"A military officer who marshals things, arranges things in methodical order..."
...czyli konwersja strumienia (sekwencji bajtów) na obiekt (unmarshall) i obiektu w strumień bajtów (marshall) ale i też forma prezentacji obiektu w pamięci. Przedstawię to na przykładzie, rysunek (rys. 3) pochodzi z artykułu Sam'a Brodkin'a, JavaWorld.com, 12/28/01 [23].
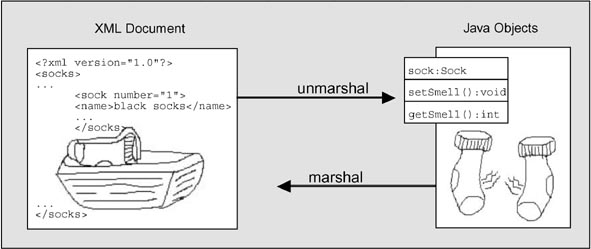
Rys. 3
Po co nam te operacje? Chyba najlepiej będzie, jak przytoczę tu cytat z tego samego artykułu:
"The ability to work with unmarshaled XML documents would be great because I could use and maintain regular Java objects much more easily and naturally than I could with a bunch of XML parsing code."
Obie te operacje (marshal/unmarshal) mogą być przeprowadzone poprzez użycie takich klas jak: org.exolab.castor.xml.Marshaller/Unmarshaller. Do dyspozycji mamy też klasę: org.exolab.castor.xml.XMLContext, która odpowiedzialna jest za konfigurację całego środowiska.
Castor może pracować w trzech trybach:
- działanie na podstawie introspekcji (używany jest mechanizm refleksji),
- na podstawie deskryptorów (2 odmiany: runtime i compile time) klas,
- przy użyciu zewnętrznych plików, które określają "mapping" pomiędzy XML'em a klasą JAVA.
Binding pozwala nam w sposób programowy dostać się do zawartości dokumentu XML (przechowywanej w pamięci) bez przechodzenia przez cała strukturę dokumentu (DOM, JDOM), dlatego też jest to dość wydajne rozwiązanie. Castor narzuca tu pewien wyższy poziom abstrakcji, pozwala na dostęp do danych zawartych w dokumencie przy pomocy modelu obiektowego. Narzędzia, które wykorzystują SAX API lub DOM API bardziej skupiają się nad strukturą dokumentu niż nad danymi, które są w nim zawarte. Ponadto dane traktowane są jako string'i i muszą być cast'owane na odpowiedni typ.
W naszym systemie na razie nie będziemy używać tej biblioteki, więc nie będę się dalej rozpisywał. Zostawię to tylko jako informację. Więcej (odnośnie API) można znaleźć na stronie Castora:
http://www.castor.org/reference/html-single/index.html#XML%20data%20binding
Wracając do biblioteki generującej kod źródłowy, należy wspomnieć, że od wersji 1.0.2 obsługiwane jest generowanie kodu zgodnego z Java 5.0, parametryzacja kolekcji i czy też możliwość używania złożonych enumeratorów. Jednak żadna z tych rzeczy nam się nie przyda, ponieważ nasz kod wynikowy musi poprawnie skompilować się jedynie pod Java 1.1.
Proces tworzenia klas można odpalić na trzy sposoby:
1. Z linii komend
2. Task w ANT
3. Plugin w Maven
Wszystko, co będzie nam potrzebne, znajduje się w artefakcie castor-codegen-1.2.jar. Biblioteka konfigurowana jest przy pomocy pliku castorbuilder.properties. Plik ten umieszczony jest w katalogu: org/exolab/castor/builder (jest to domyślny plik konfiguracyjny, Castor użyje go, kiedy nie znajdzie na classpath żadnego innego. Najważniejszą rzeczą, która zmienimy w tym pliku, będzie właściwość:
org.exolab.castor.builder.jclassPrinterTypes=\
org.exolab.castor.builder.printing.WriterJClassPrinter,\
org.exolab.castor.builder.printing.TemplateJClassPrinter
Wartość ta określa, jaka klasa odpowiedzialna będzie za generowanie kodu wynikowego. Domyślnie jest to:
org.exolab.castor.builder.printing.WriterJClassPrinter,
czyli prosta klasa, która posłuży nam później za szablon dla naszego projektu.
W pliku tym możemy znaleźć komentarz:
# It can be changed programmatically
# by calling Sourcegenerator.setJClassPrinter(fullyQualifiedClassName)
Jednak w samej klasie SourceGenerator nie udało mi się tej metody znaleźć (http://www.castor.org/1.2/javadoc/org/exolab/castor/builder/SourceGenerator.html).
Plik ten daje nam też możliwość podania nazwy nadklasy, która będzie rozszerzana przez naszą klasę (org.exolab.castor.builder.superclass), wymuszenia generowania klas opakowujących zamiast prymitywów ( org.exolab.castor.builder.primitivetowrapper), czy też tworzenia kodu zgodnego wyłącznie z Java 1.4 (org.exolab.castor.builder.javaVersion).
Podczas generowania kodu implicite korzystamy z klas Apache Velocity [24]. Klasa TemplateJClassPrinter odpowiedzialna jest za inicjalizację silnika Velocity. Między innymi ładowany jest plik:
/org/exolab/castor/builder/printing/templates/library.vm, który np. zawiera makra do tworzenia JavaDocs czy sygnatur metod.
Drugi plik:
/org/exolab/castor/builder/printing/templates/main.vm
jest głównym szablonem używanym przy generacji kodu.
Jeżeli nie dodamy odpowiednich bibliotek (velocity-1.6.1.jar) do naszego classpath to dostaniemy taki błąd:
java.lang.NoClassDefFoundError:
org/apache/velocity/context/Context
To jest mój pierwszy artykuł (oby nie ostatni) więc z góry przepraszam za wszelkie niedopowiedzenia, literówki i błędy. W następnej części dowiemy się jak praktycznie wykorzystać tę wiedzę, stworzymy dwa projekty. Pierwszy będzie odpowiedzialny za logikę dodawania do generowanych klas metod read() i write() (faza generate-sources), drugi będzie uruchamiał cały mechanizm, korzystając z Maven'a i ANT'a. Mam nadzieję, że komuś się to przyda.
Linki
[1] http://java.sun.com/j2se/1.3/docs/guide/serialization/spec/serialTOC.doc.html
[2] http://en.wikipedia.org/wiki/Marker_interface_pattern
[3] http://www.java.com/en/download/faq/what_kvm.xml
[4] http://developers.sun.com/mobility/configurations/questions/vmdiff/
[5] http://java.sun.com/products/cldc/wp/ProjectMontyWhitePaper.pdf
[6] http://www.ibm.com/developerworks/websphere/zones/wireless/weme_eval_runtimes.html?S_CMP=rnav
[7] http://na.blackberry.com/eng/developers/started
[8] http://www.doja-developer.net
[9] http://j2me.synclastic.com/2006/07/25/revisiting-j2me-object-serialization/
[10] http://www.w3.org/2006/02/Sierra10022006.pdf
[11] http://www.j2mepolish.org
[12] http://www.garret.ru/serme.html
[13] http://en.wikipedia.org/wiki/JavaBeans
[14] https://jaxb.dev.java.net/
[15] http://xmlbeans.apache.org/
[16] http://www.castor.org/reference/html-single/index.html#xml.code.generator
[17] http://soa-j.org
[18] http://www.youtube.com/watch?v=-R-vA_Tc2fM
[20] http://www.beautifulcode.nl/arborealis/
[21] http://sourceforge.net/projects/jbind/
[22] http://sourceforge.net/projects/jxquick/
[23] http://www.javaworld.com/javaworld/jw-12-2001/jw-1228-jaxb.html?page=1
[24] http://www.apache.net.pl/velocity/engine/1.6.1/velocity-1.6.1.zip


Nobody has commented it yet.