
CouchDB - bo dane to nie zawsze tabele
CouchDB jest nowym rodzajem bazy danych. Nie jest to baza relacyjna, ani też obiektowa. CouchDB przechowuje dokumenty. Dokument jest czymś w rodzaju znanej z Javy kolekcji Map, ma klucze i wartości. Kluczem zawsze jest String (oczywiście unikalny w ramach jednego dokumentu), co do wartości możliwości jest znacznie więcej, o czym dalej. Kolejną ciekawą cechą CouchDB jest to, że dokumenty te są dostępne przez RESTowy interfejs i protokół HTTP, zapisane w JSONie, znanym JavaScriptowcom formacie zapisu złożonych danych (a więc obiektów). Językiem jaki został użyty do napisania CouchDB jest Erlang, autorzy wybrali go bo świetnie nadaje się do pisania aplikacji wielowątkowych, więc CouchDB jest bardzo dobrze skalowalna na wiele procesorów/rdzeni.
Instalacja
Na stronie http://couchdb.apache.org dostępny jest plik .tar.gz z bazą, dodatkowo w Ubuntu dostępny jest pakiet couchdb. W trakcie instalacji pakietu, utworzony zostaje użytkownik couchdb. Aby odpalić bazę z tym użytkownikiem:
sudo -i -u couchdb couchdb -b
Wraz z bazą uruchamia się serwer HTTP z narzędziem administracyjnym pomocnym przy wykonywaniu operacji. Otwarcie w przeglądarce strony http://localhost:5984/ powinno skutkować pojawieniem się napisu powitalnego: {"couchdb":"Welcome","version":"0.10.0"}. Wspomniane narzędzie znajduje się pod adresem http://localhost:5984/_utils/ Nazywa się Futon. Pozwala na tworzenie i usuwanie baz danych, rekordów (dokumentów) oraz ich modyfikację.
Dokumenty
Futon jest dość intuicyjny, dlatego nie będę opisywał w jaki sposób utworzyć lub skasować bazę danych, ale przejdę od razu do opisu dokumentu. Każdy dokument w CouchDB ma id w polu o nazwie _id. Domyślnie ID są generowane jako UUID, jednak nic nie stoi na przeszkodzie, żeby wpisać inne ID podczas tworzenia dokumentu. Pamiętajmy jednak, że raz nadanego ID nie można później zmienić, więc w polu tym nie powinny być trzymane żadne informacje. Innymi słowy pole ID powinno być używane tylko do jednoznacznego określenia dokumentu, i do niczego innego.
Drugim polem którego nie można edytować po utworzeniu dokumentu jest _rev. Jak nietrudno się domyślić, oznacza ono rewizję. Każda zmiana dokumentu w CouchDB jest zapamiętywana, tzn. możemy zawsze dostać się do dokumentu sprzed zmiany, właśnie przez rewizję.
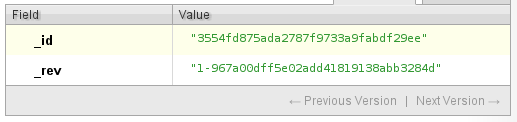
Rys. 1. Najprostszy możliwy dokument, zawierający tylko pola _id i _rev
Oczywiście do dokumentu możemy dodać też dowolną ilość innych pól. Dodawać można Stringi, liczby, listy, mapy a nawet binarne załączniki. Możliwości jest więc sporo. Wszystko to jest dość proste i intuicyjne w Futonie, trzeba tylko wiedzieć jaki format mają poszczególne typy danych.
| typ danych | format (przykład) |
|---|---|
| String | "artykuł" |
| liczba | 20 |
| tablica | [ "kot", "pies", "sikorka" ] |
| mapa | { "imię": "Paweł", "nazwisko": "Stawicki" } |
Dokumenty można tworzyć, przeglądać i edytować przez Futona, ale jak wspomniałem na wstępie, CouchDB posiada RESTowy interfejs HTTP. Aby go użyć, wykorzystamy narzędzie curl - w Ubuntu dostępne jako pakiet. Za pomocą curla możemy wysyłać komendy HTTP. Np:
curl http://localhost:5984
Powinno pokazać nam znajomy tekst powitalny.
{"couchdb":"Welcome","version":"0.10.0"}
Jeśli mamy bazę danych o nazwie tryme, komenda
curl http://localhost:5984/tryme
pokaże nam informacje o niej:
{
"db_name":"tryme",
"doc_count":9,
"doc_del_count":0,
"update_seq":54,
"purge_seq":0,
"compact_running":false,
"disk_size":106585,
"instance_start_time":"1265675480690743",
"disk_format_version":4
}
Możemy też sprawdzić, jakie bazy są dostępne:
curl http://localhost:5984/_all_dbs
["tryme","loads","training"]
lub ściągnąć konkretny dokument:
curl http://localhost:5984/tryme/61fe9c6c226b978f74b76329191806b3
{
"_id":"61fe9c6c226b978f74b76329191806b3",
"_rev":"3-f1fa64bf24600ba2ab5ad508f5bc1ab6",
"firstname":"Leszek",
"surname":"Kowalski",
"type":"person",
"position":"developer",
"salary":3000
}
To wszystko robimy poleceniem GET, zgodnie z konwencją REST. Możemy też oczywiście użyć polecenia PUT, jak nietrudno się domyślić, w celu utworzenia dokumentu lub (jeśli mamy uprawnienia administratora) bazy danych:
curl -X PUT http://localhost:5984/tryme/id1 -d '{ "firstname": "Leszek", "surname": "Gruchała" }'
{
"ok":true,
"id":"id1",
"rev":"1-12f229b1e1754562785b1caa6b52a819"
}
Utworzyliśmy właśnie rekord z dwoma polami. Jego _id to "id1". Tworząc dokumenty za pomocą Futona, nie musimy podawać ID, Futon potrafi wygenerować je za nas (a właściwie pobrać z CouchDB). W przypadku korzystania z interfejsu HTTP, musimy _id podać explicite. Nie jesteśmy jednak zmuszeni do generowania go własnymi siłami. Możemy pobrać identyfikatory z CouchDB:
curl http://localhost:5984/_uuids
{"uuids":["e0e8bb72f42f6359f9210fa4a0bb0136"]}
Możemy też pobrać (wygenerować) więcej ID na raz:
curl http://localhost:5984/_uuids?count=3
{
"uuids":["db9649f84b61cc57eb880dd34e8a0fc8",
"db2945c01d421e37af230544e4b10dcc",
"864c0c5ab116b95dd55222ab8b5bca61"]
}
Identyfikatory te są unikalne. Jeśli ktoś inny w tym samym czasie pobierze identyfikator, dostanie inny niż my.
Widok przez map/reduce
JSON pozwala na zapisanie w dokumencie różnych typów danych, w tym także... funkcji. W CouchDB jest specjalny rodzaj dokumentów nazwany design documents. W takim dokumencie możemy definiować widoki właśnie za pomocą dwóch funkcji na wzór znanego programującym w językach funkcyjnych paradygmatu map/reduce. Do utworzenia widoku wystarczy funkcja map, reduce jest konieczne do wyliczania pewnych sumarycznych wartości dla wielu dokumentów. (Może nie brzmi to zbyt jasno, ale myślę że rozjaśni się po przykładzie). Na początek zajmiemy się właśnie samą funkcją map. Jej jedynym parametrem jest dokument. W funkcji tej wołamy inną funkcję, emit, do której przekazujemy klucz i wartość. I właśnie to co wyemitujemy, znajdzie się w widoku. Myślę, że nie ma co zwlekać i najwyższy czas na przykład. Załóżmy, że mamy bazę danych z trzema prostymi dokumentami:
firstname: Paweł
surname: Stawicki
position: developer
salary: 1000
firstname: Leszek
surname: Gruchała
position: developer
salary: 2000
firstname: Ryszard
surname: Stawicki
position: manager
salary: 2500
Załóżmy, że chcemy znaleźć wszystkich developerów, i zobaczyć ich dane, funkcja map będzie wyglądała tak:
function(doc) {
if (position == "developer") {
emit(doc._id, doc);
}
}
Możemy też zrobić to inaczej, o ile nie potrzebujemy żeby kluczem było _id. Jeśli kluczem będzie position, możemy ograniczyć zwracany wynik właśnie do określonych kluczy. W tym celu jednak nasz widok trzeba zapisać pod określoną nazwą w design document. (Jest to analogiczne do tworzenia widoków w bazach SQLowych) W Futonie tworzymy Temporary view..., z następującą funkcją map:
function(doc) {
emit(doc.position, doc);
}
Widok ten zapisujemy (Save As...), podając nazwę design documentu i widoku. Załóżmy, że zapisaliśmy ten widok w design documencie o nazwie it, zaś sam widok nazwany został by-position. Dostać się do niego możemy przez następujący URL:
http://localhost:5984/tryme/_design/it/_view/by-position
{"total_rows":3,
"offset":0,
"rows":[
{"id":"61fe9c6c226b978f74b76329191806b3",
"key":"developer",
"value":
{"_id":"61fe9c6c226b978f74b76329191806b3",
"_rev":"4-7d0ecd6ca4c65ee368fc88e51fa6a3b5",
"firstname":"Leszek",
"surname":"Grucha\u0142a",
"type":"person",
"position":"developer",
"salary":2000
}
},
{"id":"eb3873f48bb581df13762324b8ec0313",
"key":"developer",
"value":
{"_id":"eb3873f48bb581df13762324b8ec0313",
"_rev":"6-b2c4d3dd7da321d286b16662ecb1f082",
"firstname":"Pawe\u0142",
"surname":"Stawicki",
"type":"person",
"position":"developer",
"salary":1000
}
},
{"id":"1",
"key":"manager",
"value":
{"_id":"1",
"_rev":"9-e3a554d649e755e1bed0d10537971e9b",
"surname":"Stawicki",
"firstname":"Ryszard",
"type":"person",
"position":"manager",
"salary":2500
}
}
]}
Teraz mamy stanowisko jako klucz. Jeśli chcemy wyświetlić samych developerów, dostępni będą pod adresem:
http://localhost:5984/tryme/_design/it/_view/by-position?key="developer"
{"total_rows":3,
"offset":0,
"rows":[
{"id":"61fe9c6c226b978f74b76329191806b3",
"key":"developer",
"value":
{"_id":"61fe9c6c226b978f74b76329191806b3",
"_rev":"4-7d0ecd6ca4c65ee368fc88e51fa6a3b5",
"firstname":"Leszek",
"surname":"Grucha\u0142a",
"type":"person",
"position":"developer",
"salary":2000
}
},
{"id":"eb3873f48bb581df13762324b8ec0313",
"key":"developer",
"value":
{"_id":"eb3873f48bb581df13762324b8ec0313",
"_rev":"6-b2c4d3dd7da321d286b16662ecb1f082",
"firstname":"Pawe\u0142",
"surname":"Stawicki",
"type":"person",
"position":"developer",
"salary":1000
}
}
]}
Powiedzmy, że w bazie danych mamy wielu developerów, managerów, administratorów i innych pracowników IT oraz ich wynagrodzenia. Aby poznać łączne wynagrodzenie dla każdej grupy zawodowej musimy wykorzystać funkcję reduce. Funkcja ta przyjmuje 3 parametry: klucze, wartości i parametr typu boolean rereduce. Z reduce zwracamy wynik, który powinien być skalarem, najczęściej liczbą. Czyli dla określonych kluczy, zwracamy liczbę, wyliczoną na podstawie wartości związanych z tymi kluczami. Klucze i wartości które trafiają do reduce, to te same klucze i wartości, które wyemitowaliśmy z map. Jest jeszcze trzeci parametr, rereduce, ale o tym później.
Nasza funkcja reduce do badania wynagrodzeń w poszczególnych grupach, powinna wyglądać tak:
function(keys, values, rereduce) {
var salaries = 0;
for(i = 0; i < values.length; i++) {
salaries += values[i].salary;
}
return salaries;
}
Za pomocą takiej funkcji reduce możemy też obliczyć łączne wynagrodzenia wszystkich pracowników. Jeśli dodamy ją do widoku it, i zapiszemy go pod nową nazwą salaries, będzie można się do niego dostać przez url:
http://localhost:5984/tryme/_design/it/_view/salaries?group_level=1
{"rows":[
{"key":"developer", "value":3000},
{"key":"manager", "value":2500}
]}
A cóż to za parametr group_level=1? Oznacza on, na jakim poziomie grupować klucze. W tym wypadku mamy tylko jeden poziom kluczy, dodamy zatem naszym pracownikom działu IT jeszcze projekty. Dodajmy pole project z wartością dla Pawła "travel", dla Leszka "houses", i dla Ryszarda też "houses". Dodajmy jeszcze jednego pracownika do projektu "houses":
firstname: Maciej
surname: Majewski
position: developer
project: houses
salary: 1800
Teraz zmodyfikujemy nieco funkcję map tak, żeby emitować klucz będący tablicą:
emit([doc.position, doc.project], doc);
Klucz jest teraz dwuelementową tablicą, ma dwa poziomy. I możemy go według tych poziomów grupować. Najlepiej zilustrować to na przykładzie. Wywołanie widoku z group_level=2 daje następujący wynik:
{"rows":[
{"key":["developer","houses"],"value":3800},
{"key":["developer","travel"],"value":1000},
{"key":["manager","houses"],"value":2500}
]}
A to wynik dla group_level=1:
{"rows":[
{"key":["developer"],"value":4800},
{"key":["manager"],"value":2500}
]}
A co się stanie jak pominiemy parametr group_level? Dostaniemy wynik zredukowany do zerowego poziomu, czyli łączne wynagrodzenie wszystkich pracowników.
{"rows":[
{"key":null,"value":7300}
]}
Widać zatem, że wynik zwracany z reduce odnosi się do grupy kluczy, i to zgrupowanych na różnych poziomach. A co robi parametr rereduce? Tak naprawdę, nasza funkcja reduce zawiera błąd i nie zadziałałaby dla dużej liczby dokumentów. To z tego powodu, że może być ona wywoływana rekurencyjnie, to znaczy najpierw przekazywana jest do niej jakaś grupa dokumentów, a potem jej wynik znowu przekazywany jest do reduce. Rereduce ma wartość false w pierwszym wypadku, a w kolejnych wywołaniach true. Teoretycznie mogłoby się tak stać w przypadku tutaj rozpatrywanym kiedy klucze są zgrupowane (group_level=1). Kolejne wywołania reduce mogłyby wyglądać następująco:
reduce (['developer'], <cały dokument Paweł>, false) => 1000reduce (['developer'], <cały dokument Leszek>, false) => 2000reduce (['developer'], [1000, 2000], true) => 3000
W pierwszym i drugim przypadku do reduce jako parametr values trafiają dokumenty, ale w trzecim przypadku trafiają tam wyniki wcześniejszych wywołań. Nie są to dokumenty ale tablica liczb, więc trzeba ją inaczej obsłużyć. Poprawna funkcja reduce powinna wyglądać tak:
function(keys, values, rereduce) {
var salaries = 0;
if (rereduce) {
salaries += sum(values);
} else {
for(i = 0; i < values.length; i++) {
salaries += values[i].salary;
}
}
return salaries;
}
Oprócz group_level, do dyspozycji mamy jeszcze między innymi parametry:
startkey- klucz pierwszego dokumentu w widoku.endkey- analogicznie, klucz ostatniego dokumentu. Przy pomocy tych dwóch parametrów możemy ograniczyć liczbę zwracanych w widoku danych.key- za pomocą tego parametru pobierzemy tylko jeden dokument, o podanym kluczu.group=true- w ten sposób możemy ustawićgroup_levelna maksimum.revs_info=true- wyświetla informacje o rewizjach dokumentu. Ma zastosowanie tylko kiedy pobieramy pojedynczy dokument (parametr key).
Design documents
Design documents służą do czegoś więcej niż tylko przechowywanie widoków map/reduce. Dzięki design documents możemy pobierane z bazy obiekty JSON "otoczyć" odpowiednim HTMLem tak, żeby zamiast kodu JavaScript zobaczyć pod adresem obiektu miłą dla oka stronę. Dobry przykład można znaleźć pod adresem http://caprazzi.net:5984/fortytwo/_design/fortytwo/index.html. Jest to w pełni funkcjonalna aplikacja webowa, w której jedynym serwerem jest serwer CouchDB. W design documencie, oprócz widoków, mogą być funkcje walidujące zapisywane dokumenty, dokonujące dodatkowych operacji na dokumencie zapisywanym do bazy, formatujące dokument do miłego dla oka HTMLa. Zajmiemy się nimi wszystkimi po kolei.
Walidacja
W design documencie możemy zdefiniować funkcję walidującą. Nie jest ona konieczna. Jeśli jej nie będzie, każdy dokument będzie uznawany za poprawny. Design documentów może być więcej, a w każdym z nich może być funkcja walidująca. Jeśli tak jest, dokument musi być zaakceptowany przez wszystkie z nich. Funkcja taka ma nazwę validate_doc_update, i następującą deklarację:
function(newDoc, oldDoc, userCtx) {}
Funkcja ta nie zwraca żadnej wartości. Jeśli uznamy dokument za niepoprawny, powinniśmy rzucić wyjątek:
throw({forbidden : "Dokument niepoprawny"});
Jeśli dokument próbuje zapisać użytkownik, któremu nie chcemy na to pozwolić ze względu na autoryzację, możemy też rzucić:
throw({unauthorized : "Dokument niepoprawny"});
W tym drugim przypadku baza poprosi użytkownika o nazwę i hasło.
Zajmijmy się teraz parametrami funkcji. Pierwszych dwóch nietrudno się domyślić, jest to nowa i stara wersja dokumentu. Jeśli funkcja wywoływana jest dla nowego dokumentu, którego jeszcze nie ma w bazie, oldDoc przyjmuje wartość null. userCtx to obiekt zawierający dane dotyczące użytkownika, np. userCtx.name.
"Dekorowanie" dokumentu
Czasem dobrze by było przesłać nie tyle dokument w formacie JSON, ale np. część dokumentu, w XMLu, CSV lub innym formacie tekstowym. CouchDB i to nam umożliwia, udostępniając funkcję show, dzięki której możemy określić co ma być zwracane zamiast "surowego" JSONa. Parametry funkcji to dokument i request:
function(doc, req) {}
Funkcja ta może zwracać zwykły tekst, wtedy jest on ładowany jako treść odpowiedzi, np:
function(doc, req) {
return '<h1>' + doc.name + '</h1><p>' + doc.bio + '</p>';
}
Możemy też określić inne parametry, np. nagłówki
function(doc, req) {
return {
body : '<h1>' + doc.title + '</h1>',
headers : {
"Content-Type" : "application/xml",
"X-My-Own-Header": "you can set your own headers"
}
}
}
Z założenia funkcja show dla takich samych parametrów, zwraca zawsze takie same wyniki, dzięki czemu można je cache'ować, co może znacznie przyspieszyć działanie bazy.
W jednym design documencie może być więcej funkcji show, różniących się nazwami.
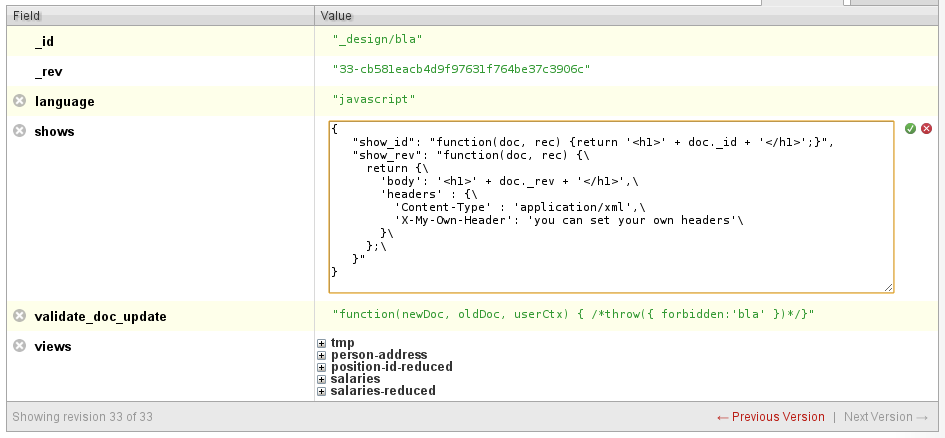
Rys. 2. Wiele funkcji show w jednym design documencie.
Pobrać dokument "udekorowany" przez taką funkcję można za pomocą następującego URLa:
http://localhost:5984/tryme/_design/it/_show/show_id/133fec564f0b68f30a7b7d63fe8235d2
Gdzie _design/it określa design document, a _show/show_id funkcję o nazwie show_id, zaś 133fec564f0b68f30a7b7d63fe8235d2 to ID dokumentu, który chcemy sobie obejrzeć.
Ciekawym rozwiązaniem jest to, że funkcję show można także wywołać bez ID dokumentu. Wtedy na miejsce argumentu doc trafia do funkcji null. Drugim parametrem funkcji show jest request, z niego możemy wyciągnąć parametry przekazane w requeście HTTP. Robi się to w sposób najprostszy z możliwych:
req.param1
Wyciągnie nam parametr o nazwie param1.
CouchDB implementuje też mechanizm template'ów, i można ich używać w funkcjach show. Możemy trzymać w osobnych plikach wzór HTMLa jakim chcielibyśmy otoczyć dokument i użyć ich w naszej funkcji. Dokładny opis korzystania z tego mechanizmu wykracza jednak poza zakres tego artykułu, odsyłam do książki online (http://books.couchdb.org/relax/)
"Dekorowanie" widoku
Innym rodzajem funkcji w CouchDB jest funkcja list. Pełni ona podobne zadanie co show, ale nie dla pojedynczego dokumentu, ale całego widoku. Przyjmuje dwa parametry:
function(head, req) {
while(getRow()) {
send(...)
}
}
head zawiera informacje potrzebne do page'ingu, czyli ile dokumentów (wierszy) pobrać oraz od którego zacząć.
req to natomiast wszelkie dane o requeście i nie tylko. Zawiera następujące parametry:
info- informacje o bazie (te same co pod URLem bazy danych, np. http://localhost:5984/tryme/)verb- GET lub POSTquery- parametry dołączone do wywołaniapath- ścieżka wywołania rozbita na części (separator: "/")headerscookiebody- przydatne jeśli wysłane było POSTemform- to co w body, ale w formacie JSONuserCtx- informacje o użytkowniku, takie same jak przesłane do funkcji validate_doc_updategetRow()pobiera następny dokument z dekorowanego widoku (nullpo pobraniu wszystkich dokumentów), asend()wysyła HTML do przeglądarki.
Na końcu funkcja list zwraca String, który również jest wysyłany do przeglądarki (może to być więc np. footer).
Aby udekorować sobie widok funkcją list, wysyła się żądanie pod następujący URL:
http://localhost:5984/tryme/_design/it/_list/basic/info
Gdzie basic to nazwa funkcji list, a info to nazwa widoku.
Bezpieczeństwo
Bezpośrednio po instalacji, z bazą danych każdy może zrobić wszystko. Pod warunkiem, że pracuje na tej samej maszynie na której stoi baza. Możemy jednak udostępnić ją światu, jednocześnie tworząc użytkowników z prawami administratorów. Jeśli jest choć jeden admin, inni użytkownicy mają już znacznie ograniczone uprawnienia. Aby utworzyć konto administratora, należy wyedytować plik /etc/couchdb/local.ini, i w sekcji [admins] dodać:
franek = haslo
Po uruchomieniu bazy, hasło zostanie zahashowane. Administratora można też dodać odpowiednim poleceniem HTTP:
curl -X PUT http://localhost:5984/_config/admins/franek -d '"haslo"'
Jeśli administrator jest już dodany, następnych może dodawać tylko on.
Jeśli chcemy wykonać jakąś operację jako administrator, nazwa użytkownika i hasło muszą być dodane do URLa:
curl http://franek:haslo@localhost:5984/tryme
Oczywiście nie jest to bezpieczne. Nazwa użytkownika i hasło, niezaszyfrowane są przekazywane przez sieć do serwera. Wystarczy podsłuchać...
Jeśli chcielibyśmy aby dostęp do naszej bazy danych mieli także użytkownicy z innych komputerów (nie tylko localhosta), trzeba jeszcze wyedytować bind_address w pliku /etc/couchdb/local.ini. Jeśli ustawimy tam wartość 0.0.0.0, do bazy będzie można się podłączyć z dowolnego komputera.
Obecnie rozwiązania bezpieczeństwa są intensywnie rozwijane w projekcie CouchDB, należy się więc spodziewać, że mechanizmy te zostaną znacznie ulepszone w niedalekiej przyszłości. Prawdopodobnie zwiększona zostanie elastyczność i będzie można ustawić jaki użytkownik do czego ma dostęp i co może z danym zasobem zrobić.
Replikacja
Kolejną zaletą CouchDB, o której dotąd nie wspominałem, jest łatwość replikacji. Za pomocą Futona można skopiować zawartość bazy danych do innej bazy praktycznie bez żadnego przygotowania. Replikację można robić zarówno z bazy lokalnej na zdalną, jak i ze zdalnej na lokalną. Nie ma tu żadnych ograniczeń.

Rys. 3. Replikacja za pomocą narzędzia "Futon"
Replikacja jest jednokierunkowa. To znaczy, że jeśli replikujemy z bazy A do bazy B, to wszystkie dokumenty które mamy w bazie A zostaną skopiowane do B, ale jeśli w B mieliśmy jakieś dokumenty których nie ma w bazie A, to nie zostaną one skopiowane do A, ani skasowane. Wynika z tego, że nie zawsze po replikacji obie bazy będą identyczne. Aby tak było, musielibyśmy zrobić dwie replikacje: A -> B i B -> A. Co ciekawe, jeśli jakiś dokument był na bazie źródłowej, ale został skasowany, przy replikacji zostanie on także skasowany na bazie docelowej.
Jeśli na bazie docelowej jest ustawione konto administratora, warto dodać jego nazwę/hasło do URLa. Inaczej dokumenty do utworzenia których uprawnienia ma tylko administrator (np. design document) nie zostaną skopiowane. W takim przypadku URL powinien wyglądać tak: http://franek:haslo@remote.com:5984/tryme
Replikację możemy przeprowadzać także lokalnie, tzn. replikować bazę danych na inną bazę danych na tym samym serwerze, tworząc w ten sposób kopię zapasową. Dzięki temu bez obaw można testować "ryzykowne" operacje, bo gdyby coś poszło nie tak, zawsze możemy łatwo i szybko przywrócić stan poprzedni.
Jedną z ciekawszych funkcji replikacji w CouchDB jest "replikacja ciągła" (continous replication). Po skopiowaniu danych CouchDB nadal nasłuchuje na zmiany na bazie źródłowej, i Kiedy takowe się pojawiają, wysyła je na bazę docelową. Nie wysyła jednak od razu, tylko w najbardziej dogodnym momencie. Dlatego nie można nigdy zakładać że jeśli mamy ciągłą replikację, to bazy zawsze będą takie same. Tym niemniej jeśli jesteśmy w stanie zaakceptować niewielkie opóźnienia w replikacji, i niewielkie różnice w danych, możliwość ta może być bardzo przydatna. Aby włączyć ciągłą replikację:
curl -X POST http://127.0.0.1:5984/_replicate
-d '{"source":"tryme", "target":"http://remote.com:5984/tryme", "continuous":true}'
CouchDB a Java
Do CouchDB powstało kilka javowych bibliotek. Jedną z nich jest CouchDB4J, jednak za jej pomocą nie udało mi się pobrać dokumentów z widoku. Być może moje dokumenty były specyficzne, jednak biblioteka nie jest rozwijana od czerwca 2009, więc prawdopodobne jest że nie będzie działać z nowymi wersjami CouchDB :(
JRelax
Druga biblioteka jaką wypróbowałem to JRelax. Tutaj bolączką jest brak dokumentacji, ale podglądająć źródła i dysponując IDE z podpowiadaniem da się to przeżyć. Tak wygląda pobranie wszystkich baz za pomocą tej biblioteki:
DefaultResourceManager manager = new DefaultResourceManager("http://localhost:5984");
List<String> dbs = manager.listDatabases();
for(String dbName : dbs) {
System.out.println(dbName);
}
Dość zaskakujący był dla mnie brak metody typu listDocuments(String dbName), aby pobrać wszystkie dokumenty (ich id) z danej bazy, trzeba użyć widoku tymczasowego:
ViewResult<String, Object> res = manager.executeTemporaryView("tryme",
"function(doc) {emit(doc._id, null)}", null, String.class, Object.class);
for(ViewResult.ViewResultRow<String, Object> row : res.getResultRows()) {
System.out.println(row.getKey());
}
Parametry metody executeTemporaryView to kolejno: baza danych, funkcja map, funkcja reduce, klasa klucza widoku, klasa wartości widoku. Typ klucza i wartości widoku musi być też podany jako typ generyczny ViewResult<K, V>, będącego rezultatem wywołania tej metody. Można tam wstawić odpowiednio przygotowane POJO, czy to zgodne z konwencją javowych beanów, czy też z annotacjami. Do mapowania JRelax używa Jacksona (parser JSONa), i na jego stronę odsyłam po szczegóły, na jakie klasy potrafi on JSONa przemapować (http://wiki.fasterxml.com/JacksonDataBinding, http://wiki.fasterxml.com/JacksonAnnotations).
Tak natomiast można zapisać dokument do bazy:
Document doc = new Document("tryme", "2", "{\"firstname\": \"pawel\"}");
manager.saveDocument(doc);
Nie znalazłem niestety możliwości podania nazwy i hasła użytkownika, więc JRelax można używać tylko do "otwartych" baz, lub tylko do odczytu. Nie znalazłem też możliwości wygenerowania id z bazy, ani przekazania parametrów startKey, endKey do wywołania widoku. Wygląda więc na to, że możliwości JRelax są dość ograniczone.
jcouchdb
Kolejną Javową biblioteką do CouchDB jest jcouchdb. Podobnie jak w przypadku JRelax, jest ona umieszczona w repozytorium Mavena, które wystarczy dodać do poma, aby Maven za nas załatwił wszystkie zależności. Pobieranie baz danych jest proste i wygodne:
Server srv = new ServerImpl("localhost");
List<String> databases = srv.listDatabases();
for(String dbName : databases) {
System.out.println(dbName);
}
Równie proste jest pobranie id wszystkich dokumentów w bazie:
Database db = new Database("localhost", "tryme");
ViewResult<Map> res = db.listDocuments(null, null);
for(ValueRow<Map> doc : res.getRows()) {
System.out.println(doc.getId());
}
Metoda listDocuments przyjmuje dwa parametry, pierwszy z nich to obiekt Options, w którym możemy ustawić parametry takie jak group, startKey, endKey itd. Drugi parametr to JSONParser, co oznacza, że możemy przekazać własny parser, który zmapuje nam JSONa na nasze obiekty, a nie tylko na mapę parametrów. Właśnie, używając domyślnego parsera możemy w dość prosty sposób odczytać dokument jako mapę:
Map<String, Object> doc = db.getDocument(Map.class, "1");
for(String paramName : doc.keySet()) {
System.out.println(paramName + ": " + doc.get(paramName));
}
Równie wygodnie można pobrać widok:
ViewResult<Map> viewRes = db.queryView("it/by-position", Map.class, null, null);
for(ValueRow<Map> row : viewRes.getRows()) {
System.out.println(row.getKey() + ": " + row.getValue());
}
Muszę przyznać, że właśnie ta biblioteka przypadła mi osobiście najbardziej do gustu.
Dlaczego CouchDB?
Rozważmy, dlaczego ktoś miałby używać nierelacyjnej bazy danych, takiej jak CouchDB, zamiast tradycyjnej, relacyjnej SQLowej. Pierwszy, dość oczywisty przykład zastosowania, to dane, które nie zawsze są takie same. Np. jeśli mamy bazę danych pacjentów, każdy ma przypisanego lekarza, ale tylko niektórzy położną, niektórzy mają przepisane leki, inni dietę, inni określone zabiegi itd. Oczywiście w bazie relacyjnej także dałoby się to osiągnąć, ale byłoby to bardziej skomplikowane, trzebaby użyć wielu tabel, obsłużyć powiązania pomiędzy nimi itd.
Inny argument przemawiający za CouchDB to elastyczność. Zwłaszcza na etapie developmentu schemat bazy danych często się zmienia. W CouchDB wprowadzanie takich zmian jest znacznie łatwiejsze - w każdej chwili możemy dopisać coś do dokumentu, nie trzeba martwić się o relacje pomiędzy tabelami.
Kolejnym argumentem przemawiającym na korzyść CouchDB jest prosty protokół HTTP/REST. Nie trzeba korzystać z żadnych sterowników (driverów) JDBC, wystarczy request HTTP żeby wykonywać operacje na bazie.
Przydatna może się także okazać funkcja wersjonowania. Przypadkowe usunięcie lub nadpisanie danych z dokumentu nie jest problemem, wystarczy przywrócić wcześniejszą wersję.
CouchDB ma też inne zalety, o mniejszym znaczeniu dla programistów pracujących z bazą danych, lecz ułatwiające życie administratorom. Jest to skalowalność i łatwa replikacja. Wszystko wskazuje na to, że kolejne procesory będą miały coraz więcej rdzeni. CouchDB nie powinna mieć problemu z wykorzystaniem dużej ich ilości. Możliwość ciągłej replikacji natomiast ułatwia zbudowanie klastra.
CouchDB, a także inne nierelacyjne bazy danych, stają się coraz bardziej popularne. Czas pokaże, czy zagoszczą na dobre na naszych serwerach.


Nie ma jeszcze komentarzy.